UNIQUESAVE= Data Set Option
Specifies to save observations with nonunique key
values (the rejected observations) to a separate data set when appending
or inserting observations to data sets with unique indexes.
| Valid in: | PROC APPEND and PROC SQL |
| Used by: | SPDSUSDS automatic macro variable |
| Default: | NO |
| Interaction: | SYNCADD=NO |
| Engine: | SPD Engine only |
Details
Use UNIQUESAVE=YES when
you are adding observations to a data set with unique indexes and
the data set option SYNCADD=NO is set.
SYNCADD=NO specifies
that an append or insert operation should process observations in
blocks (pipelining), instead of one at a time. Duplicate index values
are detected only after all the observations are applied to a data
set. With UNIQUESAVE=YES, the rejected observations are saved to a
separate data set whose name is stored in the SPD Engine macro variable
SPDSUSDS. You can specify the macro variable in place of the data
set name to identify the rejected observations.
Example: Using the UNIQUESAVE= Option with the APPEND Procedure
In the following example,
two data sets with unique indexes on the variable NAME are created,
and then appended together using PROC APPEND with UNIQUESAVE=YES.
The SAS log is shown:
1 libname employee spde 'c:\temp';
NOTE: Libref EMPLOYEE was successfully assigned as follows:
Engine: SPD Engine
Physical Name: c:\temp\
2 data employee.emp1 (index=(name/unique));
3 input name $ exten;
4 list; datalines;
RULE:----+----1----+----2----+----3----+----4----+----5----+----6----+
5 Jill 4344
6 Jack 5589
7 Jim 8888
8 Sam 3334
NOTE: The data set EMPLOYEE.EMP1 has 4 observations and 2 variables.
NOTE: DATA statement used (Total process time):
real time 9.98 seconds
cpu time 1.28 seconds
9 run;
10 data employee.emp2 (index=(name/unique));
11 input name $ exten;
12 list; datalines;
RULE:----+----1----+----2----+----3----+----4----+----5----+----6----+
13 Jack 4443
14 Ann 8438
15 Sam 3334
16 Susan 5321
17 Donna 3332
NOTE: The data set EMPLOYEE.EMP2 has 5 observations and 2 variables.
NOTE: DATA statement used (Total process time):
real time 0.04 seconds
cpu time 0.04 seconds
18 run;
19 proc append data=employee.emp2 base=employee.emp1
20 (syncadd=no uniquesave=yes);
21 run;
NOTE: Appending EMPLOYEE.EMP2 to EMPLOYEE.EMP1.
NOTE: There were 5 observations read from the data set EMPLOYEE.EMP2.
NOTE: 3 observations added.
NOTE: The data set EMPLOYEE.EMP1 has 7 observations and 2 variables.
WARNING: Duplicate values not allowed on index name for file
EMPLOYEE.EMP1. (Occurred 2 times.)
NOTE: Duplicate records have been stored in file EMPLOYEE._D3596FF.
NOTE: PROCEDURE APPEND used (Total process time):
real time 6.25 seconds
cpu time 1.26 seconds
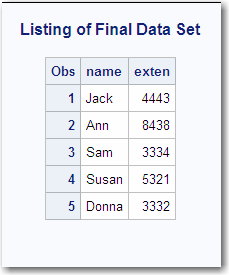
22 proc print data=employee.emp1;
23 title 'Listing of Final Data Set';
24 run;
NOTE: There were 7 observations read from the data set EMPLOYEE.EMP1.
NOTE: PROCEDURE PRINT used (Total process time):
real time 2.09 seconds
cpu time 0.40 seconds
25
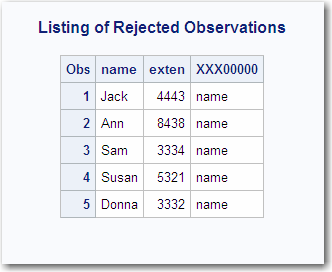
26 proc print data=&spdsusds;
27 title 'Listing of Rejected observations';
28 run;
NOTE: There were 2 observations read from the data set EMPLOYEE._D3596FF.
NOTE: PROCEDURE PRINT used (Total process time):
real time 0.01 seconds
cpu time 0.01 seconds