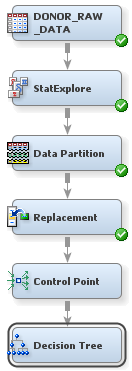
Automatically Train and Prune a Decision Tree
Decision tree models
are advantageous because they are conceptually easy to understand,
yet they readily accommodate nonlinear associations between input
variables and one or more target variables. They also handle missing
values without the need for imputation. Therefore, you decide to first
model the data using decision trees. You will compare decision tree
models to other models later in the example.
However, before you
add and run the Decision Tree node, you will add a Control Point node.
The Control Point node is used to simplify a process flow diagram
by reducing the number of connections between multiple interconnected
nodes. By the end of this example, you will have created five different
models of the input data set, and two Control Point nodes to connect
these nodes. The first Control Point node, added here, will distribute
the input data to each of these models. The second Control Point node will
collect the models and send them to evaluation nodes.
To use the Control
Point node:
SAS Enterprise Miner
enables you to build a decision tree in two ways: automatically and
interactively. You will begin by letting SAS Enterprise Miner automatically
train and prune a tree.
-
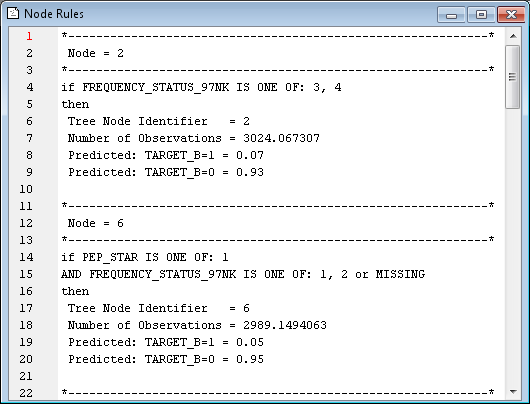
Note: The Assessment Measure subtree property is automatically set to Decision because you defined a profit matrix in Create a Data Source. Accordingly, the Decision Tree node will build a tree that maximizes profit in the validation data.
Copyright © SAS Institute Inc. All rights reserved.