Run a Hadoop SQL Program
Introduction

Use the directive Run
a Hadoop SQL Program to create jobs that execute SQL programs in Hadoop.
The directive enables you to browse available SQL functions, obtain
syntax and usage information, and click to add function syntax into
the directive’s text editor. You can also copy and paste existing
SQL programs directly into the text editor.
The user credentials
that are specified in the Hadoop Configuration panel of the SAS Data Loader Configuration window
are used to submit SQL code to the Hadoop cluster.
The Run a Hadoop SQL
Program directive enables you to use either Cloudera Impala SQL functions
or HiveQL functions.
Note: Similar support for user-written
SQL is also provided in the directives Delete Rows, Query or Join
Data, or Sort and De-Duplicate Data.
Enable the Impala SQL Environment
Support for the Cloudera
Impala SQL environment is enabled in the Hadoop Configuration panel
of the Configuration window. When Impala
is enabled, new instances of the following directives use the Cloudera
Impala SQL environment by default:
The default SQL environment can be overridden using
the Settings menu. To learn more about SQL
environments, see Enable Support for Impala and Spark.
-
Run a Hadoop SQL Program
-
Sort and De-Duplicate
-
Query or Join
Note: Changing the default SQL
environment does not change the SQL environment for saved directives.
Saved directives continue to run with their existing SQL environment
unless they are opened, reconfigured, and saved.
Example
Follow these steps to
use the directive Run a Hadoop SQL Program:
-
In the SAS Data Loader directives page, click Run a Hadoop SQL Program.
-
In the Code task, click the text editor and enter SQL code.
-
To paste SQL code, use the pop-up menu in the text editor.Note:
-
Pasted SQL must be supported in the selected SQL environment (Impala SQL or HiveQL.)
-
The SQL program needs to explicitly define data sources and targets.
-
The pop-up menu also enables you to display line numbers and to navigate to the beginning or the end of the program.
-
-
To add SQL functions to your program, click in Resources, expand categories, display syntax help, and add syntax to your program.
-
To move function syntax into your program, click the function and click
 .
.
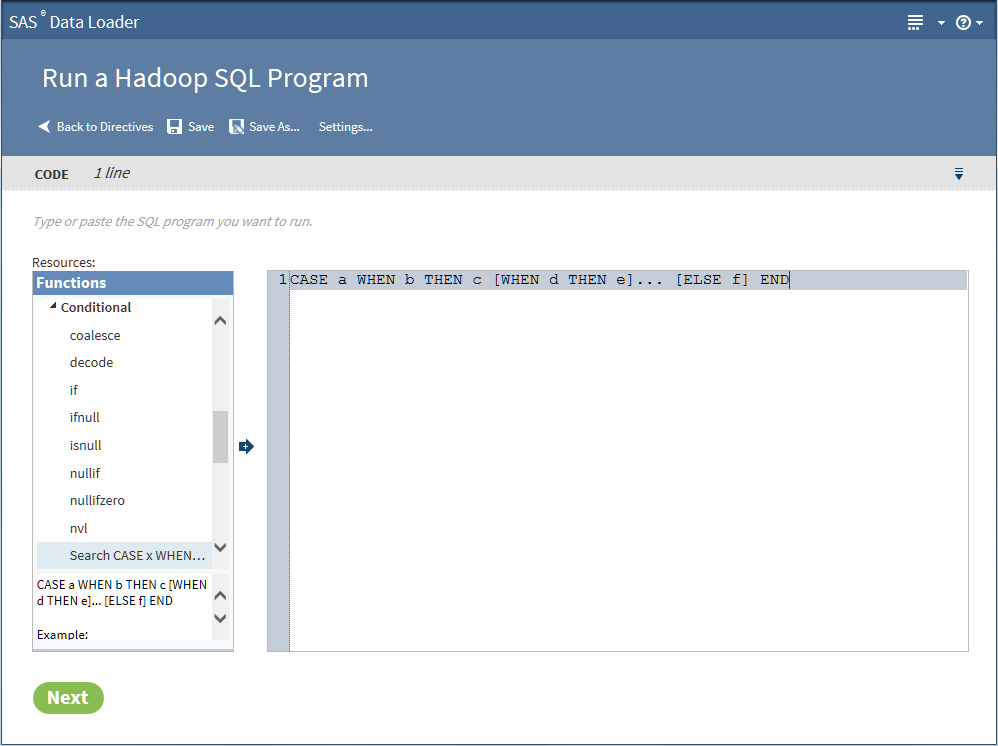
-
When your program is ready to run, click Next.
-
In the Result task, click Start SQL program. As your program runs, you receive start and end date/time information, along with Log, Code, and possibly Error Details icons. Click the icons as needed to resolve errors.The final status of the job is displayed in the Result taskbar.
-
Click Save to save your program for reuse. To edit or run your job in the future, go to the SAS Data Loader directives page and click Saved Directives.
Copyright © SAS Institute Inc. All Rights Reserved.