Change the File Format of Hadoop Target Tables
In Hadoop, tables are
stored as one or more files in the Hadoop File System (HDFS). Each
file is formatted according to the Output Table Format option, which
is specified in each file. When you create a new target table in Hadoop,
the Output Table Format option is set by the value of the Output
table format field in SAS Data Loader.
You can change the default
value of the Output table format field in
the SAS Data Loader Configuration window.
In any given directive, you can override the default value using the
Action menu icon in the Target Table task.
The default format is
applied to all new target tables that are created with SAS Data Loader.
To override the default format in a new table or an existing table,
you select a different format in the directive and run the job.
To change the default
value of the Output table format field, click
the More icon  in the top right corner of SAS Data Loader, and select Configuration.
In the Configuration window, click General
Preferences under Hadoop Configuration.
in the top right corner of SAS Data Loader, and select Configuration.
In the Configuration window, click General
Preferences under Hadoop Configuration.
in the top right corner of SAS Data Loader, and select Configuration.
In the Configuration window, click General
Preferences under Hadoop Configuration.
To override the default
value of the Output table format field for
a specific target table, open the directive, click the Action Menu
icon  on the right side of the Target Table taskbar,
and select Advanced Options.
on the right side of the Target Table taskbar,
and select Advanced Options.
on the right side of the Target Table taskbar,
and select Advanced Options.
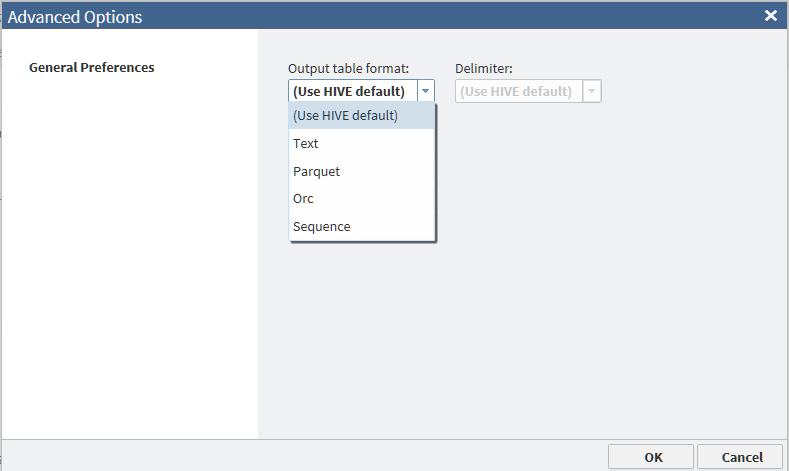
The available values
of the Output table format field are defined
as follows:
Use HIVE default
specifies that the
new target table receives the Output Table Format option value that
is specified in HDFS. This is the default value for the Output
table format field in SAS Data Loader.
Text
specifies that the
new target table is formatted as a series of text fields that are
separated by delimiters. For this option, you select a value for the Delimiter field.
The default value of the Delimiter field
is (Use HIVE default). You can also select
the value Comma, Space, Tab,
or Other. If you select Other,
then you enter a delimiter value. To see a list of valid delimiter
values, click the question mark icon to the right of the Delimiter field.
Parquet
specifies the Parquet
format, which is optimized for nested data. The Parquet algorithm
is considered to be more efficient that using flattened nested name
spaces.
Orc
specifies the Optimized
Row Columnar format, which is a columnar format that efficiently manages
large amounts of data in Hive and HDFS.
Sequence
specifies the SequenceFile
output format, which enables Hive to efficiently run MapReduce. This
format enables Hive to efficiently split large tables into separate
threads.
Consult your Hadoop
administrator for advice about output file formats. Testing might
be required to establish the format that has the highest efficiency
on your Hadoop cluster.
Copyright © SAS Institute Inc. All rights reserved.