How It Works
The following diagram illustrates the installed configuration
of SAS Data Loader.
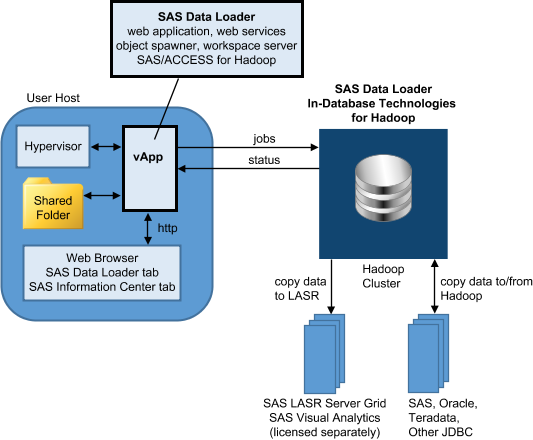
The SAS Data Loader
for Hadoop web application runs inside the vApp. The vApp is started
and managed by a hypervisor application called VMware Player Pro.
The hypervisor provides
a web (HTTP) address that you enter into a web browser. The web address
opens the SAS Data Loader: Information Center. The SAS Data Loader:
Information Center does the following:
-
starts the SAS Data Loader web application in a new browser tab.
-
provides a single Settings window to configure the vApp connection to Hadoop.
-
checks for available vApp software updates and installs vApp software updates.
All of the
files that are accessed by the vApp reside in the Shared Folder. The
Shared Folder is the only location on the user host that is accessed
by the vApp. The Shared Folder contains your saved jobs, the JDBC
drivers needed to connect to external databases, and the Hadoop JAR
files that were copied to the client from the Hadoop cluster.
When you create a job
using a directive, the web application generates code that is then
sent to the Hadoop cluster for execution. When the job is complete,
the Hadoop cluster writes data to the target file and delivers log
and status information to the vApp.
The SAS In-Database
Technologies for Hadoop software is deployed to each node in the Hadoop
cluster. The in-database technologies consist of a SAS Quality Knowledge
Base for reference to data cleansing definitions, SAS Embedded Process
software for code acceleration, and SAS Data Quality Accelerator software
for SAS DS2 methods that pertain to data cleansing.
The SAS Data Loader
for Hadoop provides the following categories of directives:
Copy data to and from Hadoop
Copy data as needed
to and from SAS and databases outside of Hadoop. Also copy data out
to SAS LASR Analytic Servers for analysis with SAS Visual Analytics
and SAS Visual Statistics.
Manage data in Hadoop
Directives support
combinations of queries, summarizations, joins, transformations, sorts,
filters, column management, and de-duplication. Data quality transformations
include standardization, parsing, match code generation, and identification
analysis, combined with available filtering and column management
to reduce the size of target tables.
Profile data
Profile jobs examine
the quality and content of tables and produce reports. The reports
are stored and managed for future reference. When you select source
and target tables for your jobs, you can open the profile reports
of the tables that have been profiled.
Manage jobs
When you create jobs,
you can save them for later execution and edit. When you run jobs,
the Run Status directive shows you the run status and enables you
to stop execution and return the job for edit in a directive.
Copyright © SAS Institute Inc. All rights reserved.