Overview of IMS Databases
Using IMS Databases
An IMS database is a large,
centralized collection of information comprising one or more physical
files that can be accessed by the SAS/ACCESS interface to IMS. An IMS database is a hierarchical database. Information is structured in records that
are subdivided into a hierarchy of related segments.
A record is a root segment and all of its dependent segments. Segments are further subdivided into fields. The data in any record relates to one entity. Ideally, information in the database
records is subdivided into segments and fields on some logical basis, either by the
inherent structure of the data or by consideration of the uses to which the data is
put.
The term hierarchical implies that there are levels of data. You can think of a hierarchical database as
one that starts at the top with general information about the item, individual,
or case. As you progress from level to level down through the hierarchy, more and
more information related to the general information at the top level is given. Each
level in the hierarchy has one or more segments.
In some ways the structures of IMS databases and tabular files (such as SAS data
sets) are comparable, but in other ways, they differ. For example, database fields
and data set variables are similar, and database records are like data set observations because
both contain data about one entity. At the same time, however, database records differ
from data set observations because subsets of records can be accessed while you cannot
access a subset of a data set observation. The observation is stored and accessed as a unit.
A tabular file has nothing comparable to a segment. The concept of data segments is one of the things that makes a hierarchical database
different from a SAS data set and other tabular files.
Consider banking data
as an example. Customer information maintained by a bank might include
the following:
|
name
|
checking account debits
|
|
Social Security number
|
checking account credits
|
|
address
|
savings account number
|
|
home phone
|
savings account balance
|
|
work phone
|
savings account date
of last statement
|
|
checking account number
|
|
|
checking account balance
|
savings account balance
at last statement
|
|
checking account date
of last statement
|
savings account debits
|
|
checking account balance
at last statement
|
savings account credits
|
If this information
is stored in a tabular file, each item of information is a variable, and all of the variables for any given person comprise one observation. You can
visualize the layout of banking data in a tabular file as shown in the following
figure.

The rows in the table
represent observations (customers), and the columns represent variables.
The structure of the file is such that a maximum number of variables
for debits and credits must be defined when the file is created. In
the previous figure there are variables for up to only three debits
and three credits per customer, which presents a problem if a customer
has more than three debit or credit transactions.
The
same data can also be stored in an IMS database but would be structured very differently. For example, the following figure
shows
one way the banking information could be structured in IMS.
The sample database, called AcctDBD, is used in this document and
described in About the Example Data in the Document.
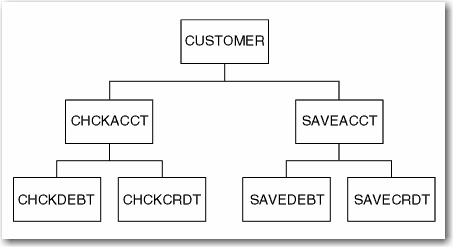
Each block in the figure represents
a segment type, which is a grouping of
related fields of data. There are three levels in the AcctDBD database hierarchy and seven segment
types. For each database record, the top or first level has only one segment, called
the root segment. The root segment in the AcctDBD database is called Customer; it contains fields
with these data: Social Security number, customer
name, address, city, state, country, ZIP code, home phone, and work phone. The segments
under the root segment are dependent segments called
CHCKACCT, CHCKDEBT, CHCKCRDT, SAVEACCT, SAVEDEBT, and SAVECRDT. Each
of the dependent segments contains fields of data, as shown in the
following table.
|
Dependent
Segment
|
Fields
|
|---|---|
|
CHCKACCT
|
checking account number,
current balance, last statement date, last statement balance
|
|
CHCKDEBT
|
checking account debit
date and time, amount, description
|
|
CHCKCRDT
|
checking account credit
date and time, amount, description
|
|
SAVEACCT
|
savings account number,
current balance, last statement date, last statement balance
|
|
SAVEDEBT
|
savings account debit
date and time, amount, description
|
|
SAVECRDT
|
savings account credit
date and time, amount, description
|
Segment Occurrences
The hierarchical database structure is useful for storing multiple occurrences of
any given element of information,
especially if there are varying numbers of occurrences of the data for each record.
Consider the dependent segment SAVEACCT, which contains the following fields:
-
savings account number
-
savings account balance
-
date of last statement
-
savings account balance at last statement
Different customers can have different numbers of savings accounts; some might have
none, others might have two or three. If the data is not segmented, there must be
space in each customer's record for the maximum number of savings accounts per customer.
With the segmented structure, however, it is possible to have one SAVEACCT segment occurrence for each savings account a customer has. Any segment type can have an unlimited number
of segment occurrences. Although the segment types are predefined, the number of
segment occurrences
is not predefined. Note that each occurrence of a root segment represents a separate
record.
Here is an example of how a segment type can have an unlimited number of segment occurrences.
A certain customer has two savings accounts. In one month, the customer
has two deposits for account number 111 and one deposit and two withdrawals for account
number 222. The following figure shows the customer's record.
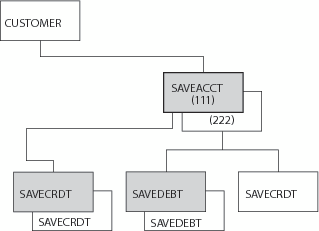
The figure shows seven segment occurrences within three (shaded) segment types.
Segment Relationships
The information in a hierarchical database is subdivided or segmented according
to a logical scheme. Moving from top to bottom
through the database, there is a relationship between the segments. A segment that
is hierarchically dependent on a segment one level up in the hierarchy is said
to be the child. The segment on which it is dependent is the parent. CUSTOMER is a parent segment with two children, CHCKACCT and SAVEACCT. CHCKACCT,
in turn, is the parent of CHCKDEBT and CHCKCRDT, and SAVEACCT is the parent of SAVEDEBT and SAVECRDT. Segments
that share a parent are called siblings; for example, CHCKACCT and SAVEACCT are siblings. Multiple segment occurrences of
one segment type with the same parent occurrence are called twins. For example, SAVEACCT 111 and SAVEACCT 222 are twins.
All dependent segments are children but are not necessarily parents. The root segment
(CUSTOMER), on the other hand, is a parent if any dependent segments exist, but it
is never a child. (It is possible to have
a database with no dependent segments, that is, with only one level, the root segment.)
In a hierarchical structure, there can be only one parent segment for a child segment.
Segments
can also be grouped by paths. Two segments belong to the same path if one is a dependent of the other. You can access multiple segments in a path at
the same time. These relationships are shown in the following figure.
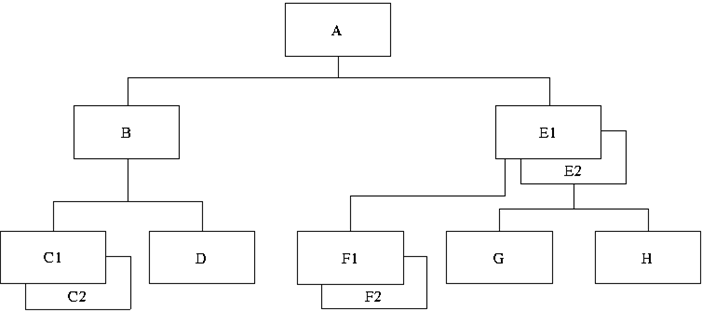
Parents:
A, B, E1, E2
Children:
B, E1, E2, C1, C2,
D, F1, F2, G, H
Twins:
C1 and C2, E1 and E2,
F1 and F2
Siblings:
B, E1, and E2; C1,
C2, and D; G and H
Paths:
A, B, and C1; A, B,
and C2; A, B, and D; A, E1, and F1; A, E1, and F2; A, E2, and G;
A, E2, and H
Path Navigation
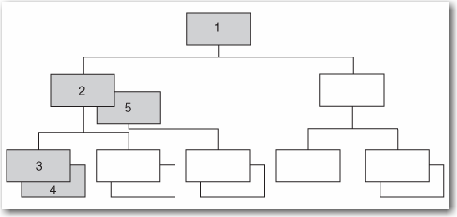
You can navigate one path of an IMS database at a time with the interface view engine in SAS 7 and later. That is, you can select items in one path of the database when
creating a view descriptor. Consider A Database Path, which shows one path of data shaded. The
SAS/ACCESS interface processes each record occurrence
from top to bottom and from left to right following these rules:
Note: No siblings are processed.
The following figure illustrates a path of data in a particular program view. The numbering indicates the order of processing.
Fields
There are three types of fields in the segments of an IMS database:
-
A sequence field (or key field) is a field that identifies and provides access to segments in a database. A sequence field is defined to IMS in the database description (DBD), which specifies characteristics of a database. In some cases, a sequence field sequences twin segment occurrences in ascending order, according to their sequence field values. For example, if the sequence field of the CHCKACCT segment is ACNUMBER, twin CHCKACCT occurrences in a given customer's record are ordered from the lowest to highest account number. Root segments usually have a sequence field, but dependent segments do not necessarily have them.In a root segment, the sequence field also uniquely identifies the record. In dependent segments, the sequence field can provide unique identification, but this is not required. Root segments might or might not be sequenced by the sequence field, depending on the IMS access method used to store the database.
-
A search fieldis defined to IMS in the DBD and is used to search through the database for particular values. For example, CUSTZIP is defined as a search field in the CUSTOMER segment, permitting the SAS/ACCESS interface to IMS to search the database for records containing a specific ZIP code.
-
An undefined field is not defined to IMS. All fields other than sequence fields and search fields do not have to be defined in the DBD. IMS does not know the format of an undefined field and cannot search for segments based on values in an undefined field. The format of an undefined field is determined by the program that loads the database initially.
The CUSTOMER segment of the AcctDBD database contains examples of two types of fields.
There are fields for Social Security number,
name, city, state, country, ZIP code, address, home phone, and work phone. The Social
Security number field is defined as the sequence field, meaning that it uniquely identifies
the record. The name field of CUSTOMER does
not uniquely identify a record because customer names might be duplicated. However,
because names can be used to search through the database, the name field is defined
as a search field, as are the address, city, state, country, ZIP code, home phone,
and work phone fields.
The sequence field of a root segment enables direct access to the root segment. The
sequence field of a dependent segment does not enable direct access to the record,
but IMS finds segments faster when searching
on sequence fields rather than search fields.
Copyright © SAS Institute Inc. All rights reserved.